Bem-vindos ao fascinante mundo do Machine Learning! Neste tutorial, vamos explorar uma técnica essencial chamada Clustering, que faz parte da Aprendizagem não Supervisionada. Mesmo que você esteja começando agora, não se preocupe! Vamos guiá-lo passo a passo, usando a biblioteca Scikit-Learn do Python, para que você possa aplicar o Clustering em seus próprios projetos.
O que é Clustering?
Imagine que você tem uma caixa cheia de diferentes tipos de frutas e quer agrupá-las de acordo com suas semelhanças. O Clustering funciona de maneira similar! É uma técnica que nos permite agrupar dados semelhantes, mesmo sem saber previamente como esses grupos devem ser. Isso é útil em várias situações, como segmentação de clientes, detecção de anomalias e muito mais.
K-means Clustering Um dos algoritmos mais populares de Clustering é o K-means. Ele funciona assim: você escolhe um número “K” que representa a quantidade de grupos (clusters) que deseja encontrar. O algoritmo então seleciona aleatoriamente “K” pontos como centros iniciais dos clusters (centroides) e atribui cada ponto de dados ao centroide mais próximo. Em seguida, ele ajusta os centroides para o centro médio de cada cluster e repete o processo até que os centroides não mudem mais significativamente.
Métodos de Inicialização de Centroides
A escolha dos centroides iniciais pode afetar o resultado final do K-means. Existem diferentes métodos para inicializá-los, como:
- Aleatório: Seleciona “K” pontos aleatoriamente como centroides iniciais.
- K-means++: Escolhe o primeiro centroide aleatoriamente e os seguintes de forma a maximizar a distância entre eles. Cada método tem suas vantagens e pode ser mais adequado dependendo do conjunto de dados.
Determinando o número de Clusters Mas como saber quantos clusters devemos usar? Existem algumas técnicas que podem nos ajudar, como:
- Método do Cotovelo (Elbow Method): Plota a soma dos quadrados das distâncias de cada ponto ao seu centroide (inertia) para diferentes valores de “K”. O ponto onde a curva forma um “cotovelo” indica um bom número de clusters.
- Silhouette Score: Mede a qualidade dos clusters com base na distância dos pontos dentro do cluster em comparação com outros clusters. Quanto maior o score, melhor a separação entre os clusters.
Voltemos ao exemplo da nossa caixa cheia de frutas diferentes, como maçãs, bananas e laranjas. Agora, você quer agrupar essas frutas com base em suas características, como cor e tamanho, sem saber previamente quantos grupos existem.
O algoritmo K-means pode ajudar nessa tarefa. Ele funciona da seguinte maneira:
- Você escolhe um número “K” que representa a quantidade de grupos (clusters) que deseja encontrar. No exemplo da cesta de frutas, vamos supor que você escolha K=3, indicando que quer agrupar as frutas em 3 grupos.
- O algoritmo seleciona aleatoriamente “K” frutas (no caso, 3 frutas) como centroides iniciais. Os centroides são os pontos centrais de cada grupo. Imagine que o algoritmo escolha uma maçã, uma banana e uma laranja como centroides iniciais.
- Em seguida, o algoritmo atribui cada fruta ao centroide mais próximo com base em suas características. Por exemplo, todas as maçãs serão atribuídas ao grupo da maçã centroide, as bananas ao grupo da banana centroide e as laranjas ao grupo da laranja centroide.
- Após a atribuição inicial, o algoritmo calcula o novo centroide para cada grupo. O novo centroide é determinado calculando a média das características de todas as frutas atribuídas a esse grupo. Por exemplo, o novo centroide do grupo das maçãs será a média das características (cor e tamanho) de todas as maçãs atribuídas a esse grupo.
- O algoritmo repete os passos 3 e 4 iterativamente. Cada fruta é reatribuída ao centroide mais próximo com base nos novos centroides calculados. Em seguida, os centroides são atualizados novamente com base nas novas atribuições.
- O processo continua até que os centroides não mudem mais significativamente ou até que um número máximo de iterações seja atingido.
Ao final do processo, o algoritmo K-means terá agrupado as frutas em 3 grupos distintos, cada um representado por um centroide. Os centroides serão as frutas “médias” ou “representativas” de cada grupo.
Por exemplo, o centroide do grupo das maçãs pode ser uma maçã de tamanho médio e cor vermelha, representando as características típicas das maçãs nesse grupo. O centroide do grupo das bananas pode ser uma banana de tamanho médio e cor amarela, e assim por diante.
Os centroides são importantes porque nos ajudam a entender as características principais de cada grupo e podem ser usados para atribuir novas frutas aos grupos existentes com base na proximidade aos centroides.
Aprenda Machine Learning em 5 Dias. Curso 100% Prático.
Melhor Preço por Tempo Limitado. Clique Aqui e Teste Sem Risco.
30 Dias de Satisfação Garantida!
Clustering com Scikit-Learn
Agora é hora de colocar a mão na massa! Vamos usar a biblioteca Scikit-Learn do Python para implementar o K-means Clustering. Primeiro, importamos as bibliotecas necessárias:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
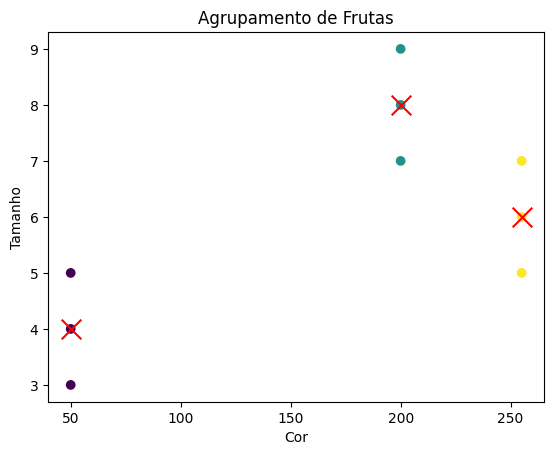
from sklearn.cluster import KMeans import numpy as np import matplotlib.pyplot as plt # Definindo as características das frutas (cor e tamanho) frutas = np.array([[255, 5], # Maçã vermelha (cor: 255, tamanho: 5) [255, 6], # Maçã vermelha (cor: 255, tamanho: 6) [255, 7], # Maçã vermelha (cor: 255, tamanho: 7) [50, 3], # Banana amarela (cor: 50, tamanho: 3) [50, 4], # Banana amarela (cor: 50, tamanho: 4) [50, 5], # Banana amarela (cor: 50, tamanho: 5) [200, 7], # Laranja laranja (cor: 200, tamanho: 7) [200, 8], # Laranja laranja (cor: 200, tamanho: 8) [200, 9]]) # Laranja laranja (cor: 200, tamanho: 9) # Criando o objeto KMeans com 3 clusters kmeans = KMeans(n_clusters=3) # Executando o algoritmo K-means kmeans.fit(frutas) # Obtendo os rótulos dos clusters para cada fruta labels = kmeans.labels_ # Obtendo os centroides dos clusters centroides = kmeans.cluster_centers_ # Plotando as frutas e os centroides plt.scatter(frutas[:, 0], frutas[:, 1], c=labels, cmap='viridis') plt.scatter(centroides[:, 0], centroides[:, 1], s=200, c='red', marker='x') plt.xlabel('Cor') plt.ylabel('Tamanho') plt.title('Agrupamento de Frutas') plt.show() |
Neste código:
- Importamos as bibliotecas necessárias:
KMeansdosklearn.cluster,numpyematplotlib.pyplot. - Definimos as características das frutas em um array
frutas. Cada fruta é representada por duas características: cor e tamanho. Usamos valores numéricos para representar as cores (255 para vermelho, 50 para amarelo e 200 para laranja) e valores numéricos para representar os tamanhos. - Criamos uma instância do objeto
KMeanscomn_clusters=3, indicando que queremos agrupar as frutas em 3 clusters. - Executamos o algoritmo K-means usando o método
fit()e passando o arrayfrutascomo entrada. - Obtemos os rótulos dos clusters atribuídos a cada fruta usando
kmeans.labels_. - Obtemos os centroides dos clusters usando
kmeans.cluster_centers_. - Plotamos as frutas usando
plt.scatter(), ondefrutas[:, 0]representa a cor efrutas[:, 1]representa o tamanho. Usamos os rótulos dos clusters para colorir as frutas de acordo com o cluster ao qual pertencem. - Plotamos os centroides usando
plt.scatter(), definindo um tamanho maior (s=200), cor vermelha (c='red') e marcador ‘x' (marker='x'). - Adicionamos rótulos aos eixos e um título ao gráfico usando
plt.xlabel(),plt.ylabel()eplt.title(). - Exibimos o gráfico usando
plt.show().
Ao executar esse código, você verá um gráfico mostrando as frutas agrupadas em 3 clusters, com cada cluster representado por uma cor diferente. Os centroides dos clusters serão marcados com um ‘x' vermelho.
E pronto! Você acabou de aplicar o K-means Clustering usando Python e Scikit-Learn. Experimente com diferentes números de clusters e conjuntos de dados para aprimorar suas habilidades.
Conclusão
Neste tutorial, aprendemos sobre Clustering, focando no algoritmo K-means. Vimos como ele funciona, os métodos de inicialização de centroides e como determinar o número ideal de clusters. Também implementamos o K-means usando a biblioteca Scikit-Learn do Python. Agora você está pronto para explorar ainda mais o mundo do Machine Learning e aplicar o Clustering em seus próprios projetos!
Lembre-se, a prática leva à perfeição. Continue explorando, experimentando e aprendendo. O céu é o limite quando se trata de Machine Learning!